
「全角英数はやめるべき」である理由
はじめに
ある新聞記者が「自分は全角(英数)派だったが、国産標準は全角ではないと言われて驚いた」という発言が、コンピュータに慣れた人々に大変な衝撃を与えています。 コンピュータを普通に使う人にとって、「全角英数を使うのは極めて邪悪な行為である」というのは当たり前のことであり、無知が故に全角英数を使う過ちを犯す人がいるのはわかるとしても、自ら全角英数をすすんで使い、かつ「全角派」を称するような人が存在することは想像だにしなかったからです。
しかし考えてみれば、コンピュータを「見た目だけ」で使っている人にとっては確かに全角か半角かは「好みの問題」に見えるかもしれません。「当たり前にわかることである」という認識は正しくないでしょう。
何が問題なのか、ここで改めて解説しましょう。
文字集合の話
規格化というのはまずその概念を明確に定めなければなりません。 なんとなく通用している曖昧な状態では厳密に共有することはできません。
コンピュータで文字を扱うため、どのような文字があるかを定め、番号を振る必要があります。
現在普及しているUnicodeは世界中の文字を内包していますが、Unicodeが普及する以前は各国にローカルな文字集合を定めていました。 日本語の文字集合はあくまで日本語を表現するものです。
日本語の文字集合でもっとも一般的なのはJISによるものです。JIS X0201にはいわゆる半角文字が入っており、追加で定義されたJIS X0208にはひらがなや漢字が入っています。
一部ギリシャ文字やロシア文字はJIS X0208に含まれているものの、ハングル文字はさらに拡張されたJIS X0213においても提議されていません。つまり、日本語文字集合では韓国語(や、タイ語やアラビア語など)は表現できません。
「日本語の」全角英数
現在はUnicodeが主流ですから、かつては別の文字集合にあった異なる言語を混ぜて書けるようになっています。
Unicodeの収録文字は各国のローカルな文字集合を元にしており、同じ意味の一部の文字は統合されています。
半角のAはU+0041 (LATIN CAPITAL LETTER A) です。対して全角のAはU+FF21 (FULLWIDTH LATIN CAPITAL LETTER A)となっており、別の文字として扱われています。
Fullwidth=全角、というまんまな表現からも分かるように、この「全角A」は日本語文字集合であるJIS X0208から来ています。 単に日本語文字集合であるというだけでなく、JIS(日本工業規格)によって定められていることからもわかるように、日本ローカルなものです。
なお、文字幅は日本で言うところの半角のものをnarrow幅、全角のものをwide幅と呼んでいます。 トランプのスペード(♠)などは、日本語文字集合では全角ですが、ラテン文字集合にも存在しており、それぞれ幅が異なることから幅はambiguous(曖昧)と定義されています。 「全角、半角」は文字高(グリフ高ではなくグリフスペース高)に対する文字幅が0.5か1.0かということを言っているのですが、特にwide characterが文字高と同じ文字幅と決まっているわけではありません。 例えば日本語等幅フォントの源ノ角 Code JPフォントは全角と半角の文字幅比は3:2です。
つまり、全角というのは日本語における慣例的表現で、FULLWIDTHというのはその直訳であり、日本語文字集合由来ということがわかります。
フォント問題
このように全角英数字というのは日本語文字集合由来なわけですが、「見た目同じだからいいじゃん」は非常に危険です。 そもそも、「見た目さえ問題なければどうでもいい」という考え方は大体の場面において好ましくは見られないでしょう。
全角英数字は見た目はラテン文字(英語など)と同じですが、定義上は日本語です。 ですから、これを表示するには日本語フォントが必要です。
日本人でヘブライ語やヒンディー語のフォントを求める人があまりいないように、ラテン語圏の人にとっては日本語フォントは縁遠いものです。 ですから、日本人にとっては日本語フォントを入れるのは当たり前であるがために全角英数字を「見た目は同じ」なんていう暴論を吐けるのですが、日本語として定義されているものである以上、非日本語圏の人にとっては「表示すらできない文字」なのです。
全角文字の由来
そもそもは木版印刷において木組みのために正方形の型を使っていた、というのが大元のようです。
活版印刷においても組みやすいように正方形を基本とし、半分幅の二分版などと組みやすいサイズを使っていたそうです。
写植においてはその必要性は薄まり、もっと自由な幅になり、これは今のプロポーショナルフォントへつながる流れとなっています。
コンピュータにおいて全角文字が必要とされたのはほぼ「縦組みのため」です。 正方形の中に文字をレイアウトすれば特別な処置をせずとも並べる方向だけで縦組みができます。 現在はかなり複雑な方法で縦組み用に文字を並べていますが、現在においても古典的なレイアウトを持つフォントもあります。例えばTフォントの等幅は正方形の中心にグリフの中心がくるようにレイアウトされており、同一の表示で縦組みも横組みもできます。
JIS X0208が定義されたのはかなり昔ですし、まだコンピュータのノウハウも薄い時期ですから、印刷の都合をなるべく反映したということです。
これは完全に、日本の中で日本的に決められたことです。
印刷物のレイアウト変化をみると、和文縦組み中の欧文は90度傾けて書くのが流行っていた時期もあるようですが、ワープロが流行した時期以降は全角を用いて同一方向にレイアウトするのが普通になっているように感じられます。
全角英数字が嫌われる訳
コンピュータにおいては文字は見た目だけの問題ではなく、コンピュータ上で計算的に扱われます。 だから、「へ」(ひらがな)でも「ヘ」(カタカナ)でも同じというわけではありませんし、「ー」(長音符)と「一」(漢数字1)のどっちでもいいわけではありません。
特にASCIIと呼ばれる英語アルファベットを中心とした文字の場合、プログラミングなどより厳密な意味を求めるケースにおいても使われます。 つまり、全角英数は「バグの原因になる」わけです。フォント構成によっては全角か半角かを見分けるのが困難な場合も珍しくありません。
下図を見てください。
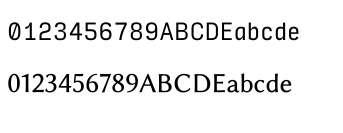
この場合、上はInput Sans Condensedで、下は源映ラテミン詰v2で描画されています。 欧文和文のフォント混在ですが、このような指定はウェブでは
font-family: "Input Sans Condensed", "GenEi LateMin P v2", sans-serif;のように書くことができ、なにも珍しいことではありません。 全体に全角のほうがむしろ幅が狭く、視覚的に全角半角を区別することができません。
これは、検索も阻むことになります。実際、全角英数が含まれているかもしれない場合、検索の手間はかなり増します。 最近は予めNFKC正規化を行うことによって全角英数をすべて半角英数にしてしまうこともできますが、結局のところそれは「全角英数が問題になるから早い段階で全角英数を排除してしまおう」という話であって、「好みの問題」で済まされているわけではありません。 この場合、ニュアンスとしては「全角入力なんてしちゃう人がいるし、そのままだと処理できないので半角英数に浄化しよう」ということになります。NKFC正規化は単に全角英数の半角化を行うわけではないので、場合によってはより面倒です。
だから全角英数は嫌われています。 これは、嫌われているというレベルではありません。強い憎悪を持って見られていると言っていいでしょう。 もしあなたが全角英数を使った場合、特に半角英数と「混ぜて」全角英数を使った場合、コンピュータ的感覚を持つ人からは「コンピュータリテラシーに欠ける人物」として蔑まれると共に胸の奥に深い怒りを抱かせることになります。
混在するケース
では全く使わないのかというと、実はそうでもありません。 特に感嘆符/疑問符、カッコ、カンマ及びピリオドに関しては日本人のハッカーでも割とよく使います。
これは、「和文をくくるカッコは和文のかっこである」というカギカッコの存在から導いた方法、漫画などで見慣れた感嘆符/疑問符の形状からこれらは全角を使う、昔からある句読点に代えてカンマ及びピリオドを使う書法において和文句読点として使用しているので全角を使う、といった理由です。
このようなケースにおいては「意味のもたせようがない」という点が重要です。 英単語や数値の場合、意味として成り立ちますが、このようなケースではそうした機能的意味を持ちません。 (もっともより解析に進めば意味をもってくるのですが、その場合は「あるものを解析する」話なので意味合いが違います)
このあたりは難しいのですが、もしも納得できないという場合のために書きました。
私の場合次の書法に従っています。
- 直前がASCII文字になる場合、ASCII文字で終える
- 接続詞なしに列挙する場合、和文句点に代えてASCIIカンマとスペースを使う
- 感嘆符は単独の場合全角!(U+FF01)または?(U+FF1F)を使う
- 現状感嘆符 U+203C, U+2049, U+2755, U+2557, U+2763, 疑問符 U+2753, U+2754, U+01C3は使わない
以前採用していて廃止した書法は以下です。 (現在は常に半角になりました)
- カッコの内容が和文を含む場合、カッコを全角にする
- ただし、通常のカッコのみでそれ以外はASCII (ブラケットなど)
見た目だけの問題ではない
実のところ、データは常にクローズドであり、決して他の人が触れることはなく、人の目に触れるのは印刷したものだけである、ということであればあまり問題はありません。 もちろん、インターネット越しの発言などはダメです。しかし、印刷の下地としてしか存在しないのであれば、別に全角英数を使っても構わないのです。1
実のところ、ワープロ時代はそうでした。「ワープロ通信」なるものもありましたが、基本的には誰かとやりとりすることはありませんでしたし、ワープロはデータ的な互換性もなかったのでデータをやりとりすることもありませんでした。 ですから、表をセルという概念のない、単に線だけを引いて見た目上表にするなんてことも当たり前に行われていました。
しかし、今は基本的にデータ交換時代です。 印刷物だけを扱い、データとしては見えないようにするなどというのは、「インターネットは見るだけでやりとりもしない」派の人でない限りなかなか難しいでしょう。
過去の話でいえば、ウェブでも1998年くらいまでは「見た目だけ」のレイアウトをしていました。 段揃えをするために列数1の表を使ったり、インデントするために項目数1で入れ子になっている箇条書きを使ったり、行間を調整するために小さなまっしろの画像を並べたり、といったことをしていました。
しかし、このような方法は邪悪であり、データは適切な構造を持つべきである、という考えは21世紀のスタンダードです。 見た目さえそれっぽければ良いというのは20世紀に置き去りにすべき未熟な考え方であり、そもそも「見た目さえよければ中身は適当でいい」というのは実生活においても大概批判されるであろう考え方でしょう。
もっとも、気持ち悪い、と批判されるかもしれませんが↩︎